이번 6월에 <신경망 첫걸음>이라는 책으로 딥러닝에 대한 기초 개념을 습득하였다.
https://www.yes24.com/Product/Goods/37883845
신경망 첫걸음 - 예스24
인류에겐 이런 딥러닝 입문서가 필요했다 딥러닝 입문자가 늘고 있지만, 수학 이론을 공부하자니 갈 길이 멀고 원리를 무시한 채 코딩부터 하자니 응용이 불가능하다. 수학 공식과 통계 이론을
www.yes24.com
https://github.com/ratel0307/Deep-Learning
GitHub - ratel0307/Deep-Learning: 딥러닝 스터디 기록용입니다
딥러닝 스터디 기록용입니다. Contribute to ratel0307/Deep-Learning development by creating an account on GitHub.
github.com
이번 포스팅에는 책의 마지막 실습인 MNIST 손글씨 데이터 인식 신경망을 직접 만들어 보는 과정을 글로 작성하겠다.
MNIST 손글씨 데이터는 두 가지 종류가 있다. 학습 데이터로 다시 테스트하면 왜곡된 점수가 나오기 때문에 이 둘을 분리한다.
1. 학습 데이터(training set): 신경망의 학습에 이용될 수 있도록 레이블(입력값 + 결과값)이 붙어 있는 60000개(100개)의 데이터
2. 테스트 데이터(test data): 알고리즘이 얼마나 잘 동작하는지 확인하기 위한 10000개(10개)의 데이터 (마찬가지로 레이블이 붙어 있음)
CSV 파일을 열면 수많은 숫자가 나열되어 있는 것을 확인할 수 있다.
여기서 첫 번째 값은 레이블이고, 레이블 이후에 나오는 쉼표로 구분되는 값들은 손글씨 숫자의 픽셀값들이다. 픽셀 배열의 크기는 28 x 28 이므로 총 784개의 값이 존재하고 각 값은 0~255중 하나의 숫자를 가진다.
각 숫자가 무슨 색을 의미하는지 궁금해서 챗GPT한테 물어보니, 0은 흰색이고 255는 검은색이며 중간값은 다양한 회색 음영을 나타낸다고 한다.
ChatGPT: 그레이스케일 이미지는 흑백 이미지라고도 하며, 각 픽셀이 밝기를 나타내는 단일 강도 값으로 표현된 이미지입니다. 그레이스케일 이미지의 픽셀 값은 일반적으로 0에서 255 사이의 정수로 표현되며, 여기서 0은 검은색, 255는 흰색을 의미하고 그 사이의 값들은 다양한 회색 음영을 나타냅니다. 이는 RGB 컬러 이미지와 다르며, RGB 이미지는 각 픽셀이 빨강(R), 초록(G), 파랑(B)의 세 가지 값을 가지는 반면, 그레이스케일 이미지는 하나의 강도 값만을 가집니다.
MNIST 학습 데이터 준비하기
지난 챕터에서 미리 만들어 놓은 인공 신경망 코드에 MNIST 데이터를 인식시키기 위해 데이터를 가공해 보겠다.
training_data_file = open("mnist_dataset/mnist_train_100.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()
for record in training_data_list:
all_values = record.split(',')
inputs = (np.asfarray(all_values[1;]) / 255.0 * 0.99) + 0.01
targets = np.zeros(output_nodes) + 0.01
targets[int(all_values[0]) = 0.99
1. 파이썬에서 학습 데이터 파일을 열고, readlines()라는 함수를 호출해서 100개의 행을 각각 리스트로 만든다.
2. split(',') 함수를 이용하여 구분자인 쉼표(,)를 기준으로 각각 문자열을 생성한다.
3. 0~255 사이에 속하는 입력 색상 값들의 범위를 0.01~1.0 사이에 속하게 조정한다. 0~255 사이의 값을 255로 나누면 0~1의 범위를 가지고 여기에 0.99를 곱한 후 0.01을 더하면 원하는 범위를 얻을 수 있다.
4. 출력 계층의 노드 수(output_nodes)를 길이로 삼는 0으로 채워진 배열을 생성하기 위해 np.zeros() 함수를 사용하고 0.01을 더한다.
5. 레이블인 all_values의 맨 첫 번째 값을 이용하여 targets의 정답 값을 0.99로 설정한다.
ex) '5'가 정답이면 targets = [0.01, 0.01, 0.01, 0.01, 0.99, 0.01, 0.01, 0.01, 0.01]
3게층의 신경망으로 MNIST 데이터를 학습하는 코드
import numpy as np
import scipy.special
import matplotlib.pyplot as plt
class neuralNetwork:
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.wih = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
self.lr = learningrate
self.activation_function = lambda x: scipy.special.expit(x)
pass
def train(self, inputs_list, targets_list):
#입력 리스트를 2차원의 행렬로 변환
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
output_errors = targets - final_outputs
hidden_errors = np.dot(self.who.T, output_errors)
#은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * np.dot((output_errors * final_outputs * (1.0 - final_outputs)), np.transpose(hidden_outputs))
#입력 계층과 은닉 계층 간의 가중치 업데이트
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), np.transpose(inputs))
pass
def query(self, inputs_list):
#입력 리스트를 2차원 행렬로 변환
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
#입력, 은닉, 출력 노드의 수
input_nodes = 784
hidden_nodes = 100
output_nodes = 10
#학습률은 0.3
learning_rate = 0.3
#신경망의 인스턴스 생성
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
#mnist 학습 데이터인 csv 파일을 리스트로 불러오기
training_data_file = open("/MNIST/mnist_train_100.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()
#신경망 학습시키기
for record in training_data_list:
#레코드를 쉼표에 의해 분리
all_values = record.split(',')
#입력 값의 범위와 값 조정
inputs = (np.asfarray(all_values[1:]) / 255.0*0.99) + 0.01
#결과 값 생성
targets = np.zeros(output_nodes) + 0.01
#all_values[0]은 이 레코드에 대한 결과 값
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass
신경망 테스트하기
#신경망 테스트
#신경망의 성능의 지표가 되는 성적표를 아무 값도 가지지 않도록 초기화
scorecard = []
#테스트 데이터 모음 내의 모든 레코드 검색
for record in test_data_list:
all_values = record.split(',')
#정답은 첫 번째 값
correct_label = int(all_values[0])
print(correct_label, "correct label")
#입력 값의 범위와 값 조정
inputs = (np.asfarray(all_values[1:]) / 255.0*0.99) + 0.01
#신경망에 질의
outputs = n.query(inputs)
#가장 높은 값의 인덱스는 레이블의 인덱스와 일치
label = np.argmax(outputs)
print(label, "network's answer")
#정답 또는 오답을 리스트에 추가
if (label == correct_label):
scorecard.append(1)
else:
scorecard.append(0)
pass
pass
print(scorecard) #60점입니다...
#정답의 비율인 성적을 계산해 출력
scorecard_array = np.array(scorecard)
print("performance =", scorecard_array.sum() / scorecard_array.size)
전체 데이터를 이용해 학습 및 테스트하기
이제 60000개의 training data와 10000개의 test data를 사용하여 나의 신경망 성적표를 산출하니 performance = 0.9405가 나왔다.
정확도를 더 개선하려면 어떤 방법을 취할 수 있을까? 가장 먼저 떠오르는 건, 학습률을 조정해 보는 것이다. 책에 따르면 학습률이 0.2일 때 성능이 최고라고 한다. 정해진 공식은 없다. 직접 해봐야 한다.
또 다른 방법은, 학습을 여러 번 반복함으로써 성능을 개선할 수 있다. 한 번의 수행을 주기(epoch)라고 하는데, 반복 작업을 하면 경사 하강법에 의해 가중치의 값이 업데이트되는 과정에서 더 많은 가능성을 제공해 준다.
하지만 너무 많이 학습하면 신경망이 학습 데이터에 과적합(overfitting) 되어 성능이 오히려 떨어질 수 있다. 책에 따르면 주기가 7일 때 성능이 최고라고 한다. 이때, 같은 주기에 대해서 학습률을 0.1로 해보면 성능이 오히려 좋아진다.
마지막 방법은, 신경망 구조를 변경하는 것이다. 책에 따르면 은닉 노드 개수가 200개일 때 성능이 최고라고 한다.
*이렇게 경험이나 실험을 통해 결정하는 값을 하이퍼파라미터(hyperparameter)라고 한다.
따라서 이를 바탕으로 다시 코드를 짜보면 다음과 같다.
import numpy as np
import scipy.special
import matplotlib.pyplot as plt
class neuralNetwork:
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.wih = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
self.lr = learningrate
self.activation_function = lambda x: scipy.special.expit(x)
pass
def train(self, inputs_list, targets_list):
#입력 리스트를 2차원의 행렬로 변환
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
output_errors = targets - final_outputs
hidden_errors = np.dot(self.who.T, output_errors)
#은닉 계층과 출력 계층 간의 가중치 업데이트
self.who += self.lr * np.dot((output_errors * final_outputs * (1.0 - final_outputs)), np.transpose(hidden_outputs))
#입력 계층과 은닉 계층 간의 가중치 업데이트
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), np.transpose(inputs))
pass
def query(self, inputs_list):
#입력 리스트를 2차원 행렬로 변환
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
#입력, 은닉, 출력 노드의 수
input_nodes = 784
hidden_nodes = 200
output_nodes = 10
#학습률은 0.3
learning_rate = 0.1
#신경망의 인스턴스 생성
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
#mnist 학습 데이터인 csv 파일을 리스트로 불러오기
training_data_file = open("/mnist_train.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()
#신경망 학습시키기
#주기 5로 설정
epochs = 5
for e in range(epochs):
for record in training_data_list:
#레코드를 쉼표에 의해 분리
all_values = record.split(',')
#입력 값의 범위와 값 조정
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
#결과 값 생성
targets = np.zeros(output_nodes) + 0.01
#all_values[0]은 이 레코드에 대한 결과 값
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
pass
test_data_file = open("/mnist_test.csv", "r")
test_data_list = test_data_file.readlines()
test_data_file.close()
#신경망 테스트
#신경망의 성능의 지표가 되는 성적표를 아무 값도 가지지 않도록 초기화
scorecard = []
#테스트 데이터 모음 내의 모든 레코드 검색
for record in test_data_list:
all_values = record.split(',')
#정답은 첫 번째 값
correct_label = int(all_values[0])
#입력 값의 범위와 값 조정
inputs = (np.asfarray(all_values[1:]) / 255.0*0.99) + 0.01
#신경망에 질의
outputs = n.query(inputs)
#가장 높은 값의 인덱스는 레이블의 인덱스와 일치
label = np.argmax(outputs)
#정답 또는 오답을 리스트에 추가
if (label == correct_label):
scorecard.append(1)
else:
scorecard.append(0)
pass
pass
scorecard_array = np.asarray(scorecard)
print("performance =", scorecard_array.sum() / scorecard_array.size)

나만의 손글씨 데이터로 실험해보기
내가 직접 그림판으로 손글씨 데이터를 생성해서 실험해 보면 어떨까?
이미지가 정사각형으로 폭과 길이가 같게 만들고, 파일 포맷을 png로 만들어 28 x 28픽셀에 맞춰 조정해 주자.

다음은 내가 그린 2, 7, 9 손글씨 데이터이다.


책에 나오는 scipy.misc가 작동하지 않아서, 챗GPT에게 물어보았더니 from PIL import Image 코드를 추천해 주었다.
숫자 7을 먼저 테스트해 봤다. 여기서 255를 빼는 이유는 관행적으로 0은 검은색을, 255는 흰색을 의미하는데 MNIST 데이터 모음은 이와 반대로 구성되어 있기 때문이다.

결과는 3이 나왔다. 왜 이러지? 다른 숫자도 테스트해 봤다.

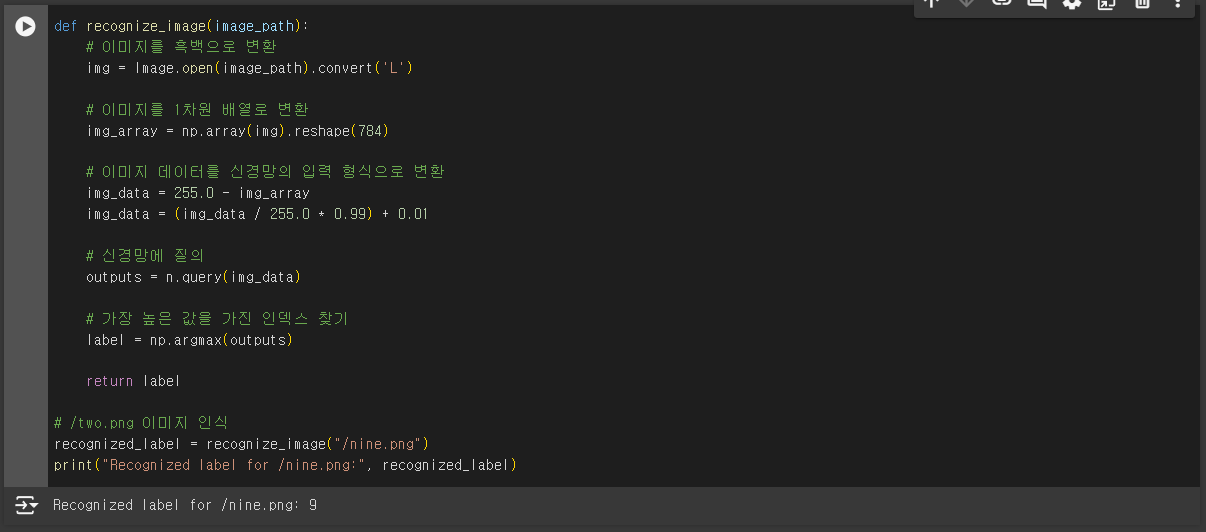
2와 9는 인식을 잘 한다.
오기가 생겨서 7을 다른 방식으로 그려서 테스트해 봤다.


이제야 제대로 나왔다! 7을 그릴 때 꽁지를 그리냐 안 그리냐에 따라서 결과가 달라진 사실을 알게 되었다.
이로써 나의 신경망 첫걸음이 막을 내렸다. 내가 배운 이론을 직접 코드로 구현하고, 이를 테스트까지 해보는 과정을 혼자의 힘으로 수행해서 뿌듯하다.
7월부터는 <밑바닥부터 시작하는 딥러닝 1권> 책을 스터디하고자 한다.
'AI' 카테고리의 다른 글
| [AI 논문] CLIP: Learning Transferable Visual Models From Natural Language Supervision (2021) (2) | 2024.09.07 |
|---|---|
| [AI 논문] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2024.09.04 |
| [AI 논문] Attention Is All You Need (2017) (3) | 2024.09.03 |
| [AI 논문] Show and Tell: A Neural Image Caption Generator (2015) (4) | 2024.08.25 |
| 합성곱 신경망(CNN)을 파헤쳐 보자! (0) | 2024.08.12 |



