처음엔 그저 재밌어보여서 시작한 AI 공부를 벌써 4개월 째 하고 있다.
이젠 책으로 공부만 하는 건 지겹고 실제 프로젝트를 해보고 싶었다.
마침 고려대학교 의료빅데이터연구소에서 9~10월 동안 '방광암 WSI 기반 병리 보고서 생성 모델 개발'이라는 주제로 대회를 개최한다는 소식을 듣고 해당 주제에 관심 있는 동기들과 함께 지원하였고, 운이 좋게 선발이 되었다.
* 대회 사이트
https://k-medicon.com/sub2.html
MEDICAL CONTEST
Urinary bladder, transurethral resection; Invasive urothelial carcinoma, with 1) squamous differentiation 2) invasion to muscularis propria Note) The specimens include muscle proper.
k-medicon.com
대회 주제를 단순화시켜보면, image -> text 이다. 이와 관련된 기술을 Image Captioning이라고 한다.
지금까지 내가 공부한 지식으로는 'CNN과 RNN을 연결시켜서 어떤 모델을 만드는 거겠지?' 라고만 추측이 된다...
그래서 Image Captioning 논문을 찾다가, CVPR 2015에 publish된 'Show and Tell: A Neural Image Caption Generator' 논문을 발견하였다.
예전 자료이지만, 여전히 이 분야의 근본(?) 논문이라고 하니 지나칠 수가 없어서 읽고 공부한 내용을 정리해보았다!
참고로 글을 쓰는 목적은 순전히 내가 공부하면서 고민한 흔적을 기록하기 위해서다. 그러니 이 글을 통해 전문적인 지식을 체계적으로 얻고자 하는 사람은 뒤로 가기를 누르고 다른 글을 찾는 것을 추천...
* 본글의 모든 그림은 아래 논문 본문과 유튜버 동빈나님의 발표 영상에서 가져왔습니다.
논문 전문: https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdf
논문 설명 영상(한글): https://www.youtube.com/watch?v=yfsFW-mfOEY&list=PLRx0vPvlEmdADpce8aoBhNnDaaHQN1Typ&index=31
Abstract
CV와 NLP를 연결하는 AI 기술 중, 사진을 묘사하는 글을 자동으로 생성하는 task는 fundamental problem이다.
그래서 이 논문에서는 recent CV & machine translation을 활용해 generative model을 제시하고자 한다.
그렇다면 모델이 어떻게 훈련되었나? maximize the likelihood of the target description sentence give the training image!
Likelihood, MLE
여기서 잠깐, likelihood가 뭐지? 또 이를 maximize하네?
내가 지금까지 공부했던 ML/DL 모델 훈련 방식은 다음과 같다.
손실함수를 계산 -> 손실함수를 최소화하는 방향으로 매개변수(가중치와 편향)을 업데이트!
근데 여기서는 1) likelihood를 2) maximzie 하네?
그래서 이 개념을 ChatGPT한테 물어봤다.
Q.
ML/DL 모델을 훈련시킬 때 손실함수를 최소화하는 방법을 사용한다고 원래 알고 있었어. 근데 논문을 읽다가 likelihood를 maximize하는 방법도 있다는 걸 알게 되었어. 이에 대해 자세히 알려주겠지? 우선, likelihood라는 개념에 대해서 먼저 알고 싶어.
A.(답변을 나의 방식대로 다시 정리)
Likelihood(우도)란 주어진 데이터가(데이터가 관측된 상태에서) 어떤 확률 분포에서 발생했을 가능성(특정 확률 분포에 대한 믿음의 정도)을 의미한다.
공식적으로, likelihood 함수는 다음과 같이 정의됩니다:
L(θ∣X) = P(X∣θ)
그럼 likelihood는 probability, 즉 확률이랑 같은 개념 아닌가?
그건 아니다.
probability는 정해진 분포(θ)로부터 data가 발생할 확률을 예측하는 거라면,
likelihood는 고정된(관측한) data이 주여졌을 때 우리가 정한 분포(θ)에서 그 data가 나올 확률을 의미한다.
즉, likelihood는 θ에 관한 함수다.
이때, likelihood를 maximize하는 것과 관련된 keyword가 바로 Maximum Likelihood Estimation(최대우도추정)이다.
머신러닝의 목적 자체가 주어진 데이터로부터 이 데이터를 잘 설명하는 분포를 찾는 것으로도 볼 수 있으니, 둘은 일맥상통하는 거 아닐까?
그럼 MLE를 어떻게 구할까?
만약 관측값이 하나면 위 공식으로 구하면 되겠지만, 여러 개라면?
이 관측값들이 서로 독립적이라면, 각 관측치에 대한 우도들의 곱으로 나타낼 수 있다.
L(θ∣X=x1,x2,...,xn) = L(θ∣X=x1) ∗ L(θ∣X=x2) ∗...∗ L(θ∣X=xn)
그리고 이 식의 미분을 편리하게 하기 위해 로그를 취하여 곱셈을 덧셈으로 바꾼다(log-likelihood).
여기에다가 마이너스를 붙이면 negative log-likelihood가 되는데
결국 log-likelihood를 최대화하는 건 negative log-likelihood를 최소화하는 것과 같다.
따라서 손실함수는 negative log-likelihood라고 볼 수 있겠지!
다시 본문으로 돌아와보자.
이 모델은 (그때 당시) state-of-the-art인 image caption 모델보다 특정 데이터셋에 대해 BLEU-1 score이 높았다.
이 특정 데이터셋이 무엇이 있는지, 그리고 BLUE-1 score가 아직 무엇인지 모르지만,
어떤 것을 개선해서 점수를 올렸는지가 이 논문을 읽는 데 핵심이 아닐까 싶다!
1. Introduction
논문 읽는 건 처음인데, 이런 저런 논문 읽는 법을 찾아보다가 각자 방식이 다 다름을 느끼고
일단 시간이 걸리더라도 내가 처음부터 끝까지 읽어보고 나만의 방식을 만들어보기로 했다!
읽다 보니 '논문이 이런 flow로 쓰이는 구나'도 알게 되어서 1석 2조인듯!
Introduction 맨 처음에는 Image captioning 기술이 사회에서 어떻게 도움이 되는지 서술한다.
helping visually impaied people better understand the content of images on the web
오...그렇긴 하겠네...근데 그 글자 또한 안 보인다면? 이라는 생각이 잠깐 스쳐갔다.
image captioning 기술은 classification이나 recognition tasks보다 어렵다고 한다.
또한, object를 capture하는 것뿐만 아니라 이들간의 관계 또한 서술해야 함을 강조한다.
(당연하게, language model도 필요하고)
기존 연구법은 어땠는가? 이미 연구된 모델들을 이어붙여 하나의 모델을 만들려고 했다.
근데 본 논문에서는 기존 연구법과 달리 하나의 모델(end-to-end)을 제시한다.
즉, CNN을 통해 이미지를 encoding하고, 이 값이 자연스럽게 RNN으로 전달되어 텍스트를 decoding하는 하나의 모델을 만들었다고 볼 수 있다! (더 자세히 말하면, CNN의 last hidden layer을 RNN의 input으로 사용한다.)
이를 논문에선 Neural Image Caption(NIC)라고 명칭한다.

이 논문의 contribution은 다음과 같다.
1. end-to-end system을 만듦 -> SGD로 훈련 가능.
2. 그 당시 state-of-art sub-networks를 combine함. -> 추가 data로 훈련 가능
3. 기존 모델에 비해 better performance!
2. Related work
건너뛰고 나중에 읽어보겠다. 처음부터 지치면 지속가능하지 않기 때문! 변명 아님.
3. Model

위 식을 해석해보자.
우리는 주어진 I(이미지 데이터)에 대응되는 S(텍스트 데이터)이 나올 확률을 최대화하는 theta를 찾아야 한다.
아까 살펴본 likelihood 개념이네?
이를 계산하기 위해 P(S|I)를 구하고 로그를 씌우면 다음과 같다.

위 식을 최대화(- 씌운 값은 최소화)하는 theta를 찾으면 그만!
그럼 어떻게 modeling하냐? 이때 등장하는 게 CNN과 LSTM(RNN 계열)이다.
아래를 보면 seq2seq와 유사한 아키텍처를 쓴다.
동빈나님에 따르면 2021년 기준으로 최신 고성능 모델은 Transformer 아키텍처를 기반으로 한단다. (지금은 또 다르려나...?)
CNN, RNN, LSTM, seq2seq에 관한 내용을 이 글에 모두 담는 것은 무리라고 생각한다.
그러니 추후에 이와 관련된 논문 공부 글을 또 포스팅 링크를 달아야지!



CNN은 ImageNet으로부터 pre-trained되어 있다.
CNN으로부터 image data가 x-1로 임베딩되어 LSTM 계층에 입력된다.
위 손실함수는 아래의 매개변수를 모두 다룬다.
1. LSTM
2. top layer of the image embedder CNN
3. word embeddings We
최적화 방법으로 SGD를 쓰고 과적합 방지 위해 Dropout과 emsembling을 쓴다.
4. Experiments
평가 지표
- 자동 평가 지표로 BLUE-4를 주로 사용
데이터셋

- Pascal VOC 2008, Flickr8k, Flickr30k, MSCOCO, SBU 데이터셋을 사용해 모델을 평가
- MSCOCO가 가장 좋은 데이터셋
결과

- Table 1을 보면 MSCOCO datasets에 대해 NIC 모델이 다른 모델보다 모든 평가 지표가 모두 높다.
- Table 2을 보면 다른 데이터셋에 대해서도 NIC가 다른 모델보다(human) 제외 BLUE-1 score가 모두 높다.
Human Evaluation
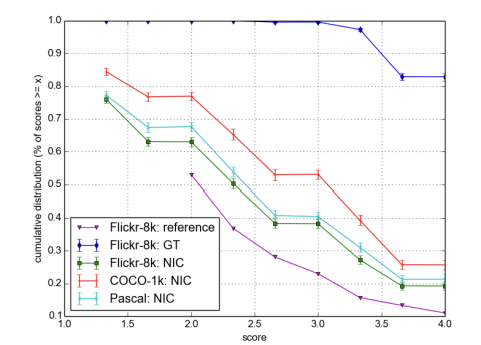
- NIC 모델이 다른 시스템보다 더 나은 성능을 보였지만, 여전히 인간이 생성한 문장보다는 성능이 떨어짐.
- BLEU 점수가 인간 평가와 완벽하게 일치하지 않음을 확인.
5. Conclusions
- 이미지 설명 데이터셋의 크기가 커질수록 NIC와 같은 접근 방식의 성능이 더욱 향상될 것!
- 앞으로도 비지도 학습 방법을 적용하는 것도 흥미로울 것!
6. 후속 연구
기존 seq2seq 모델의 한계는 뭐냐?
바로 context vector의 크기가 고정되어 있어.
NIC를 예를 들면 CNN으로부터 인코딩된 데이터의 크기가 고정된다는 거겠지?
이 문제를 해결하는 것이 너무나도 유명한 attention 메커니즘!
attention은 디코더가 인코더의 모든 출력을 참고한다.
Neural Image Caption Generation with Visual Attention (ICML 2015) 논문에서는 NIC 네트워크에 어텐션(attention) 기법을 적용한다!!

따라서 나는 일단 attention에 관한 논문을 공부한 뒤 위 논문을 봐야겠음!
7. 논문을 통해 배운 점
- 논문을 쓰는 flow를 알게 되었다. -> 기존 연구의 한계와 이를 어떻게 개선했는지 객관적인 실험을 통해 서술!
- likelihood과 probability이 어떤 차이를 가지고 있는지 명확히 알게 되었다. -> MLE는 주어진 데이터에 대하여 그 데이터를 가장 잘 표현하는 매개변수를 찾는 것!
'AI' 카테고리의 다른 글
| [AI 논문] CLIP: Learning Transferable Visual Models From Natural Language Supervision (2021) (2) | 2024.09.07 |
|---|---|
| [AI 논문] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2024.09.04 |
| [AI 논문] Attention Is All You Need (2017) (3) | 2024.09.03 |
| 합성곱 신경망(CNN)을 파헤쳐 보자! (0) | 2024.08.12 |
| MNIST 손글씨 데이터 인식 신경망 직접 만들어 보기 (0) | 2024.06.24 |



