k-medicon 대회를 준비하기 위해 딥러닝 논문을 리뷰한 글을 처음 포스팅한 게 벌써 2달 전이다.
https://www.k-medicon.com/sub2_score.jsp
MEDICAL CONTEST
Urinary bladder, transurethral resection; Invasive urothelial carcinoma, with 1) squamous differentiation 2) invasion to muscularis propria Note) The specimens include muscle proper.
www.k-medicon.com
https://apple2jobs.tistory.com/62
[AI 논문] Show and Tell: A Neural Image Caption Generator (2015)
처음엔 그저 재밌어보여서 시작한 AI 공부를 벌써 4개월 째 하고 있다.이젠 책으로 공부만 하는 건 지겹고 실제 프로젝트를 해보고 싶었다.마침 고려대학교 의료빅데이터연구소에서 9~10월 동안 '
apple2jobs.tistory.com
패기 있게 시작했지만, 대회 준비 과정에서는 많은 우여곡절이 있었다.
이번 블로그 포스팅에서는 경진대회 문제해결 프로세스에 따라 우리의 결과물을 소개하고, 대회를 통해 얻은 값진 교훈들을 나누고자 한다.
사실, 후자가 더 의미 있다고 생각한다. 실전 경험을 통해 책으로 공부한 것보다 몇 배 더 많은 깨달음을 얻었기 때문이다.
경진대회 문제해결 프로세스
(아래 순서는 <머신러닝,딥러닝 문제해결 전략> 책을 참고하였다.)
1. 경진대회 이해
- 문제 이해: 경진대회의 배경과 목적을 이해하는 것이 먼저다. 어떤 데이터를 사용해 어떤 값을 예측해야 하는지, 회귀 문제인지 분류 문제인지 등을 명확히 파악하자.
- 평가지표 파악: 경진대회 평가지표를 확인한다. 같은 모델을 사용하더라도 평가지표에 따라 등수가 달라질 수 있어 중요하다.
2. 탐색적 데이터 분석 (EDA)
- 데이터 구조 탐색: 주어진 데이터의 구조를 간단히 살펴보고 몇 가지 통계를 계산해본다.
- 데이터 시각화: 그래프를 활용하여 데이터의 전반적인 특성과 패턴을 파악한다.
3. 데이터 전처리
- 데이터의 결측값 처리, 이상치 제거, 변환 등을 통해 모델 학습에 적합한 상태로 데이터를 준비한다.
4. 베이스라인 모델
- 머신러닝은 복잡한 기술이므로, 처음부터 최고 성능의 모델을 만들려 하지 말고 기본 모델을 만들어보는 것이 좋다.
- 데이터 준비: 파이토치의 경우 전용 데이터셋 클래스와 데이터 로더를 생성한다.
- 모델 훈련 및 성능 검증: 간단한 모델을 생성, 훈련하여 성능을 확인한다.
5. 성능 개선
- 결과 예측 및 제출: 훈련된 모델을 활용해 테스트 데이터를 사용하여 예측 결과를 제출한다.
- 다양한 아이디어를 적용하여 모델의 성능을 높인다. 결과가 기대에 미치지 못하면 이전 단계로 돌아가서 다시 시도해본다. 성능이 개선된 모델을 활용해 최종 결과를 예측하고 제출한다.
1. 경진대회 이해
문제 이해
대회의 주제는 ‘방광암 WSI 기반 병리 보고서 생성 모델 개발’이다.
일반적으로 병리 의사들은 환자의 검체 슬라이드를 현미경으로 관찰하여 직접 병리 보고서를 작성한다. 그러나 병리 의사의 수가 줄어들고 노령 인구의 증가로 검사 수요가 증가하면서, 이러한 노동 집약적인 작업을 자동화함으로써 비용 절감 효과를 기대할 수 있게 되었다.
스캐너와 컴퓨터 기술의 발전으로 슬라이드를 완전히 디지털화하는 ‘디지털 병리’가 빠르게 발전하고 있다. 이러한 디지털화된 슬라이드 이미지인 WSI를 입력값으로 받아 병리 보고서를 출력하는 모델을 만들 수 있지 않을까?
결국, 이미지 데이터를 텍스트로 변환하는 것이 목표이다. 이렇게 여러 종류의 데이터를 다루는 모델을 멀티모달 모델이라고 한다.
평가 지표
평가 지표는 아래와 같다.
- A. Word score: ROUGE-L, BLEU-4
- B. Keyword score: Scispacy Jaccard
- C. Embedding score: GPT3 활용하여 similarity 측정
- D. Mean Opinion Score (MOS) : Private test 한해 평가 예정
이 네 가지 지표를 활용하여 public test score와 private test score를 산출하며, 이 두 점수를 통해 최종 점수를 계산한다.
* 교훈 1: ‘SOTA 모델을 쓰면 무조건 좋은 평가지표를 받는다’라는 생각을 버리자. 대회 심사 기준을 명확히 파악하고, 그 기준에 맞는 모델을 선택하는 것이 중요하다.
* 교훈 2. 대회 규정을 잘 숙지하자. 특히 대회 기간을 정확히 파악해야 한다. 이번이 처음이어서 Leaderboard 운영 방식에 대해 잘 알지 못했지만, 이제는 public 및 private test score와 관련된 개념을 이해하게 되었다.
2. 탐색적 데이터 분석 (EDA)
WSI 파일은 용량이 매우 커서 RAM이 충분해도 QuPath 프로그램에서 이미지를 여는 데에 몇십 초가 걸렸다. 이로 인해 이미지를 원활하게 탐색하지 못했고, 데이터에 대한 충분한 이해가 어려웠다.
하지만 데이터를 충분히 이해하는 과정은 필수적이다. 앞으로는 이를 명심하며 대회에 임해야겠다.
* 교훈 3: 모델을 선택하기 전, 데이터를 충분히 이해해야 한다. 이를 위해 전처리 전에 EDA(탐색적 데이터 분석)를 수행하는 것이 가장 중요한 과정이다.
3. 데이터 전처리
- 이미지 데이터: WSI 이미지는 2배 축소되어 512×512 픽셀 크기의 패치로 변환했다. 배경 패치는 RGB thresholding과 edge detection 을 통해 제외하였고, 과도한 여백이 있는 패치는 제거하였다.
- 텍스트 데이터: 병리 보고서는 BioGPTTokenizer를 사용하여 토큰화하였다.
4. 베이스라인 모델
우리는 직접 아키텍처를 설계하는 대신, 오픈 소스 코드를 활용하기로 결정했다. 이를 위해 비슷한 문제를 다룬 논문들을 찾아보았고, 저자들이 GitHub에 공개한 코드를 이용할 수 있는지 확인했다.
이러한 조건을 고려한 끝에 최종적으로 ‘HistoGPT’ 모델을 선택하고 이 모델을 우리의 주제에 맞게 변형했다.
https://github.com/marrlab/HistoGPT
GitHub - marrlab/HistoGPT: A vision language model for gigapixel whole slide images in histopathology
A vision language model for gigapixel whole slide images in histopathology - marrlab/HistoGPT
github.com
https://www.medrxiv.org/content/10.1101/2024.03.15.24304211v2
Generating clinical-grade pathology reports from gigapixel whole slide images with HistoGPT
Histopathology is considered the reference standard for diagnosing the presence and nature of many malignancies, including cancer. However, analyzing tissue samples and writing pathology reports is time-consuming, labor-intensive, and non-standardized. To
www.medrxiv.org
이 모델은 사실 피부 병리 데이터를 기반으로 학습된 모델이어서, 보고서 생성 시 피부 병리와 관련된 용어가 나올 가능성에 대해 우려가 있었다. 그러나 제한된 자원과 촉박한 대회 준비 기간을 감안했을 때, 대회 성과보다는 경험을 쌓자는 취지로 이 모델을 선택해 도전하게 되었다.
데이터 준비
이미지와 텍스트 특징은 파일 이름을 기준으로 정렬하여 맞추었고, 데이터셋은 70:15:15 비율로 training, validation, and testing 세트로 나누었다.
모델 아키텍쳐
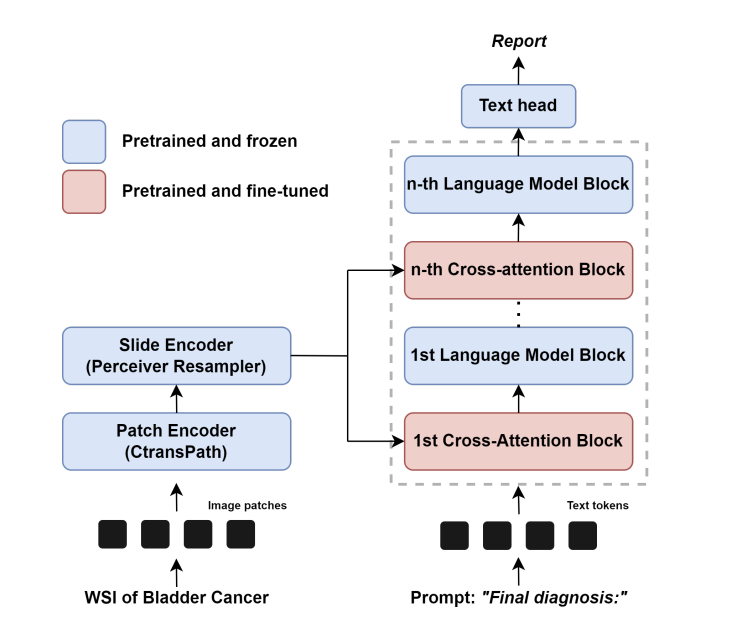
- Patch Encoder: WSI는 겹치지 않는 패치들로 나누어진 후, 사전 학습된 CTransPath를 통해 인코딩되었다.
- Slide Encoder: HistoGPT의 사전 학습된 Perceiver Resampler를 통해 가변적인 패치 벡터들이 고정된 개수의 시각적 출력으로 압축되었다.
- Gated Cross-Attention Blocks: HistoGPT의 사전 학습된 크로스 어텐션 블록을 사용하여 시각적 특징과 BioGPT를 연결하였다.
- Language Model: BioGPT가 시각적 및 토큰화된 입력을 바탕으로 텍스트를 생성하였다.
모델 훈련 및 성능 검증
Fine-tuning 단계에서는 크로스 어텐션 블록만 학습되었고, 다른 계층들은 고정되었다. 학습의 안정성을 위해 학습률 스케줄링과 가중치 감쇠가 적용되었다. 성능 평가는 “Final diagnosis:”라는 프롬프트를 사용하여 새로운 WSI에 대해 병리 보고서를 생성하는 방식으로 이루어졌다.
* 교훈 4. 과적합을 피하는 것이 예상보다 훨씬 중요하다. 이를 위해 데이터 양을 늘려야 하며, 데이터 증강이 중요한 역할을 한다.
5. 성능 개선
테스트 데이터셋을 사용해 훈련된 모델을 실제로 실행해 본 후 대회 측으로부터 점수를 받았다.
성능 개선에 충분한 시간을 할애하지 못했지만, 다음 대회에서는 이 과정에 더 집중할 계획이다.
대회가 끝난 만큼 이제 한숨 돌리고 재정비할 시간을 가지려 한다.
계속해서 화이팅해보자!
'AI' 카테고리의 다른 글
| [AI 논문] CLIP: Learning Transferable Visual Models From Natural Language Supervision (2021) (2) | 2024.09.07 |
|---|---|
| [AI 논문] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2024.09.04 |
| [AI 논문] Attention Is All You Need (2017) (3) | 2024.09.03 |
| [AI 논문] Show and Tell: A Neural Image Caption Generator (2015) (4) | 2024.08.25 |
| 합성곱 신경망(CNN)을 파헤쳐 보자! (0) | 2024.08.12 |



